Tools
| .NET | .NET Core | |
|---|---|---|
| Platform | Windows | Linux, Mac, Windows, ARM |
.NET and .NET Core are the programs that translates C# files into instructions for the CPU. They both contain,
- CLR (Common Language Rumtime) - the runtime (or space) to run the programs in C#
- FCL (Framework Class Library - also known as Base Class Library, the library to perform common activities such as communicate over the network over HTTP, manage files etc.
The .NET Core SDK contains the CLR, FCL and other tools that make developing software easier. These tools include dotnet, the .NET CLI (short for Command Line Interface). The common commands are:
dotnet new [options]- scaffold a new projectdotnet add package <PACKAGE_NAME>- add a NuGet package to the projectdotnet add reference <PROJECT_PATH>- add a project-to-project reference to the projectdotnet restore- restore dependencies i.e. NuGet packagesdotnet build- compile the source code i.e. the C# compiler translates all.csfiles into a.dllbinary file (an assembly). Works on both the.csprojfile and the.slnfile.dotnet run- restore, build and run the projectdotnet <assembly.dll>- run the assemblydotnet test- run unit tests using the test runner specified in the.csprojfile. Also works on solution file i.e..sln.dotnet sln- modify the solution file
A project is a collection of source code files that you want to put together into a single application or library that you write to share with other developers. You can create a new project using dotnet new from the command line.
Typical folders/files in a project,
.csproj- the project configration file. It contains reference to NuGet packagesbin/Debug/netcoreapp2.2- binarry, debug and SDK versionobj/- temporary files that are put together during the restore and build process- other source files
NuGet is the package system for .NET and .NET Core. External packages are referenced in the .csproj file and can be restored using the dotnet restore command.
What dotnet run actually does
The dotnet run command implicitly does a few things behind the scene,
-
restoring the dependencies by running
dotnet restore, -
compiling the source code by running
dotnet build. The compilation process involves,-
Using the compiler to transform or translate the source code into an efficient binary format that is faster to excute when we need to actually run the application.
-
Putting all
.csfiles into a single.dllfile.- The
.dllin the context of .NET and .NET Core is called an assembly (rather than Dynamic Link Library).
- The
-
-
providing the proper runtime and launching the application by running
dotnet [path-to-application-assembly]
TIP: Add
--to separeate application parameters from the dotnet parameters. i.e. rundotnet run -- A B Cto make sure the valuesA,B, andCare passed to the application, rather than being passed to the CLI.
What is a solution ?
A solution file keeps track of multiple projects and is understood by Visual Studio or the .NET CLI i.e. dotnet. For example, dotnet build will build all projects in a solution and dotnet test will find all unit testing projects in the solution and run the unit tests. To create a solution file, run dotnet new sln at the top level of the collection of projects.
Keywords:
static- The static keyword associates members (i.e. methods or fields in a class) to the class rather than its instances (i.e. objects) of a class. Static fields are mostly used to track some global states across all objects of the same class. Static methods are usually behaviours that have nothing to do with specific objects of the class.internal- Access modifier that makes a class only accessible inside a project. Good for internal classes that are implementation details of your project and you don't want to expose them publicly. Thepublicmodifier exposes a class to consumer of the project. If no access modifier is specificed for a class, the class is treated asinternalby default.
Unit test is testing a small unit of code, e.g. a method in a class, and verify that it's working as intended. The convention in C# is to create a separate project with the name <project_name>.Tests. A great side effect of writing unit tests is that it forces you to think about the design of your code.
Tip: if you try to describe what a class does or what a single method does, and you have to use a conjunction word like **_and_**, there is a chance that it's doing too many things. In this case, you should break your class or method up.
Reference type vs value types
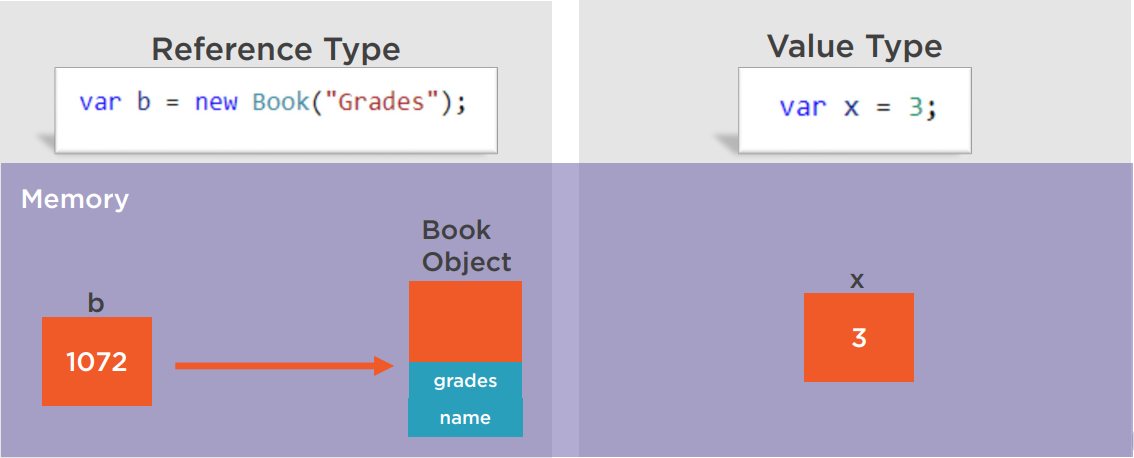
Tip: the keywords are "memory address".
Passing by value
// Passing by value
var a = ... // imagine we declared and initialised a variable
f(x) { ... } // we also defined a function somewhere
f(a) // We then execute the function by passing in the variable `a`
In C#, when passing a variable (e.g. the variable a in var a = ...) to a method (e.g. the method f(x)), we are always, 100% of the time, passing the parameter by value. It means, we always copy the value held by the variable (i.e. a), instead of the memory address of the variable a. The held value could be a memory address if the variable holds a reference to an object or the actual value if variable holds the actual value.
Passing by reference
Passing a variable by its reference to a method allows (inside) that method to update the content of the variable. So,
- If the variable holds the memory address of some object, the method can change which object the variable is pointing to if it wants to, in addition to update the object.
- If the variable holds a value, the method can update the value held by the variable.
In C#, passing a variable by reference is achieved by using the ref keyword,
var book = new Book("Book 1");
GetBookSetName(ref book);
void GetBookSetName(ref book)
{
// your code here
}
or using the out keyword
var book = new Book("Book 1");
GetBookSetName(out book);
void GetBookSetName(out book)
{
// out assumes the reference has not been initialised
book = new Book();
}
Unlike ref, with the out keyword, the C# compiler assumes that the incoming reference has not been initialised. The compiler will give an error if the out parameter is not assigned in the GetBookSetName method.
How to tell if a variable is reference type or value type
A class type is a reference type and a struct type, including int (alias for Int32), double (alias for Double), bool (alias for Boolean), DateTime, char etc., is a value type.
Similarities between reference type and value type
A struct type is similar to a class type in that it can have fields and methods.
Differences between reference type and value type
A reference type is usually mutable while a value type is immutable.
For example, an object is mutable because we can change it's properties. But if we have the number 3, we cannot really change that value and we cannot re-assining the meaning of integer 3.
NOTE: We can assign both a reference type and a value type to variables, which is not what we're talking about here. We're talking about if the object/value itself is mutable.
Special case - string is immutable
A string (alias for String) is a reference type but behaves like a value type. Like a value type, a string object is immutable and all of the methods on that object creates a copy of the original object.
Garbage Collection
One of the services that the .NET runtime (the CLR) provides is a garbage collector. So the .NET runtime can keep track of all the objects that you have allocated and created, and it also keeps track of and knows about all the variables you've created and all the fields that you have inside of objects that point to other objects that are in memory. And the .NET runtime knows when there's an object in memory, it knows when there's no variables and no fields that are pointing to or using that object. And it knows when that happens, when nothing is using that object, it can run a garbage collection and clean up and deallocate that object. That frees up memory so your program doesn't exhaust memory.
Conventions
- Use PascalCase for public members i.e. methods, fields etc. of a class.
Flow control
Execution always goes from top to bottom. Flow controls include,
iffor branching,foreach,do ... while,while,forfor loopingbreak,continuefor jumping statementsswitchfor switching
// C# 7 and later supports switch with pattern matching
switch(a)
{
case var aa when <predicate>: // aa will take on the value of a
...
break;
...
default:
...
break;
}
Building Types
Fields and Methods
Fields and methods in a class are both members of that type. The C# compiler determines if two methods are the same by looking at their signature, which contains:
- the name of the method,
- parameter types,
- number of parameters
The return type of a method is not part of the signature for that method.
Properties
A field is the variable representing the state of the object, while a property is the field + the getters and setters of that backing field.
// a backing field for the property
private string name;
// property
public string Name {
get {
return name;
}
set {
name = value;
}
}
And it can be written as an auto property as below
// the C# compiler will automatically generate a private backing field with the getters and setters as shown above.
public string Name { get; set; }
Defining an auto property is very similar to defining a public field with the same name. However, there are a couple of differences between them,
- The main differences revovle around reflection and serialisation, which both inspect an object to see what's available for state at runtime.
- Another difference is that the getter and setter of a property can have different access modifiers. e.g. one is private while the other is public.
Readonly fields
A readonly field can only be set by a variable initialisor or in the constructor. And the compiler will throw an error if it's set in a method. It's good for states that are set at the object creation time but never are changed for the rest of the object life cycle.
// initializer
readonly string Cateogry = "Science";
// or initialise in constructor
...
Const fields
const has a stricter rule than readonly - it can only be set by an initializer and is not even able to be set inside a constructor. Because it's not tied to a particular object, it's accessed via the type name rather than the object. That is, const fields are treated as static members of the class.
// initializer
public const string CATEGORY = "Science"; // by convension, all const values use upper case for the name of the field.
Delegates
A delegate is a specific type, just like double (alias for Double), string (alias for String), Book in class Book {} etc, that describes what a method looks like including the return type of the method and the sequence of parameters of the method.
namespace GradeBook {
// for comparision
public class Book {}
// define delegate
public delegate string WriteLogDelegate(string logMessage);
}
Then somewhere,
namespace Gradebook.Tests
{
public class
{
[Fact]
public void WriteLogDelegateCanPointToMethod()
{
WriteLogDelegate log;
// 1st way: similar to how an object is constructed from a class definition
log = new WriteLogDelegate(ReturnMessage);
// 2nd way
log = ReturnMessage;
// invoking the delegate
var result = log("Hello");
Assert.Equal("Hello", result);
}
string ReturnMessage(string message)
{
return message;
}
}
}
A multi-cast delegate is a delegate that contains multiple methods and can invoke all methods at once. Example,
namespace Tests
{
public delegate string WriteLogDelegate(string message);
public class Foo.Tests
{
[Fact]
public void DelegateCanMultiCast
{
WriteLogDelegate log;
log = MethodA;
log += MethodA;
log += MethodB;
// MethodA will be called twice and MethodB will be called once i.e. multi-cast
var result = log("Hello");
}
string MethodA(string message)
{
// ...
}
string MethodB(string message)
{
// ...
}
}
}
Events
A method of an object might want to generate some event and invoke some methods defined elsewhere.
An example of defining and raising an event using delegate,
namespace GradeBook
{
// should go into a separate file as it's its own type similar to a class
public delegate void GradeAddedDelegate(object sender, EventArgs args);
public class Book
{
// the `event` keyword add further restrictions and additional capabilities to the delegate that make the delegate safer to use.
// example restriction such as forbiding the use of the assignment operator
public event GradeAddedDelegate GradeAdded;
public void AddGrade(char letter)
{
// publish event
GradeAdded(this, new EventArgs());
}
}
}
and an exmaple of handling the event is,
class Program
{
static void Main(string[] args)
{
var book = new Book();
// add event handlers
book.GradedAdded += OnGradeAdded1;
book.GradedAdded += OnGradeAdded2;
book.GradedAdded += OnGradeAdded2;
book.GradedAdded -= OnGradeAdded2;
// can't use assignment operator on `event`, such as wiping out all methods in delegate
// book.GradeAdded = null;
}
static void OnGradeAdded1(object sender, EventArgs e)
{
// ...
}
static void OnGradeAdded2(object sender, EventArgs e)
{
// ...
}
}
Object-oriented Programming (OOP)
The three pillars of OOP:
-
Encapsulation allows us to hide details about our code. e.g. methods, properties, access modifiers etc.
-
Inheritance allows us to reuse code from similar classes.
namespace Test { public class A { public string Name {get; set;} public A(string name) { Name = name; } } // inheritance is denoted by the `:` symbol public class B : A { public B(string name) : base(name) // chain constructors for initialising properties in base object. { // initialise other properties in class B. } } }Every class has a base class; if not specified, the base class is the
System.Objectclass. A struct also inherits from theObjectclass; so a value type is technically also a reference type. -
Polymorphism allows us to have objects of the same type (e.g. an abstract base class or an interface) to behave differently.
One way to achieve polymorphism is by inheriting from an abstract class and providing implementation for the abstract methods. For example, a
Bookobject (the real type could be different) canSaveGrade()to in memory, disk or over the network.public class NamedObject { public NamedObject(string name) { Name = name; } public string Name {get; set;} } public abstract class Book : NamedOjbect { public Book(string name) : base(name) { } // Only defines the signature and return type of the method that any descendant classes should have. // No implementation details are provided at this level. public abstract void AddGrade(double grade); } public class InMemoryBook : Book { public Book(string name) : base(name) { } // the override keyword tells the comiler to override the inherited abstract or virtual method. public override void AddGrade(double grade) { // store grades in memory } }var inMemoryBook = new InMemoryBook("hi"); foo(inMemoryBook); public foo(Book book) { // AddGrade here is polymorphic - its behaviour changes depending on the actual type of `book` (rather than the base type `Book`). book.AddGrade(96); }Another way to achieve encapsulation and polymorphism is by definning an interface.
-
An interface contains no implementation details and it only describes the members that should be available on a specific type.
-
An abstract class contains some implementation details and some abstract methods.
-
A class has all implmentation details.
No access modifier for methods are needed in an interface because the implementing type must always make the method public.
public interface IBook { string Name {get;} void AddGrade(double grade); Statistics GetStatistics(); event GradeAddedDelegate GradeAdded; } public class InMemoryBook : IBook { }public void foo(IBook book) { // ... }
-
Difference between an abstract method and a virtual method,
- An
abstractmethod is saying the deriving class must override me, - a
virtualmethod is saying I have provided implmention details, but deriving class can still override me if it needs to.
In both cases, the derived class needs the override keyword for a method if that method overrrides the parent version.
The IDisposable interface is implemented by many classes to advertise that they have something to be cleaned up, freed or released. The garbage collector will eventually free up the resources, but sometimes we want these resoruces to be freed immediately on demand.
The implementing class usually has a .Close() method as well as the .Dispose() method. These two methods typically do the same thing - asking the garbage collector to free up the underlying resources.
When working with an object that implements IDisposible, an easy pattern to make sure the .Dispose() method is called is,
void foo()
{
// When wrapping a statement with using, the `using` keyword is telling the compiler that we are using the `writer` object and it needs to always call the `.Dispose()` method on the object after all statements in the code block are executed.
// The c# compiler will generate a try ... catch ... finally code to make sure the `.Dispose()` method is called.
using(var writter = File.AppendText("test.txt"))
{
// ...
}
}
Non-nullable Reference Types
The C# compiler can aggresively look through our programs to find places where we might have null reference exception at rumtime. This behaviour can be turned on/off in the .csproj file and it's enabled by default for the C# 8.
By default, all reference types are non-nullable, but a varialble can be null by adding a ? after the type. e.g.
Book? book;